This case study shows Multi-Sigma® can build a surrogate model for a tsunami simulator and to predict waveform data.
1. Building a Surrogate Model with Multi-Sigma®
Building a surrogate model for waveform data with Multi-Sigma® requires some ingenuity. As a first step, to construct a surrogate model, the simulator must be run multiple times in advance, and the corresponding input and output data are then used to train the AI model.

One approach to training an AI model is to convert a time-series forecasting task into a multi-output regression problem (Fig. a → Fig. b). Rather than performing sequential prediction, this approach trains the AI model to output the tsunami value at each time point 𝑡𝑖 as part of the model’s output.
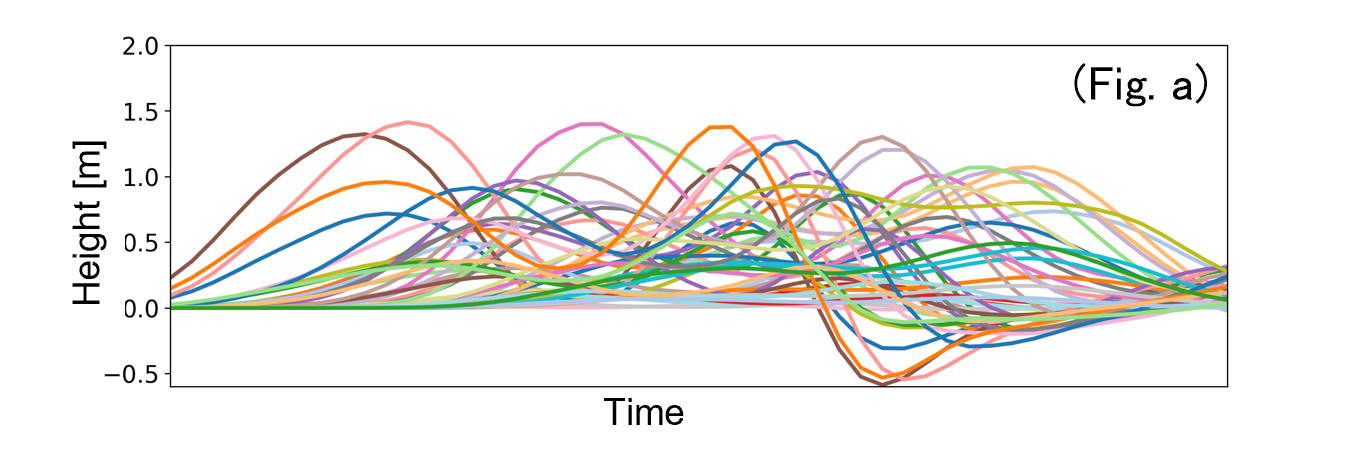

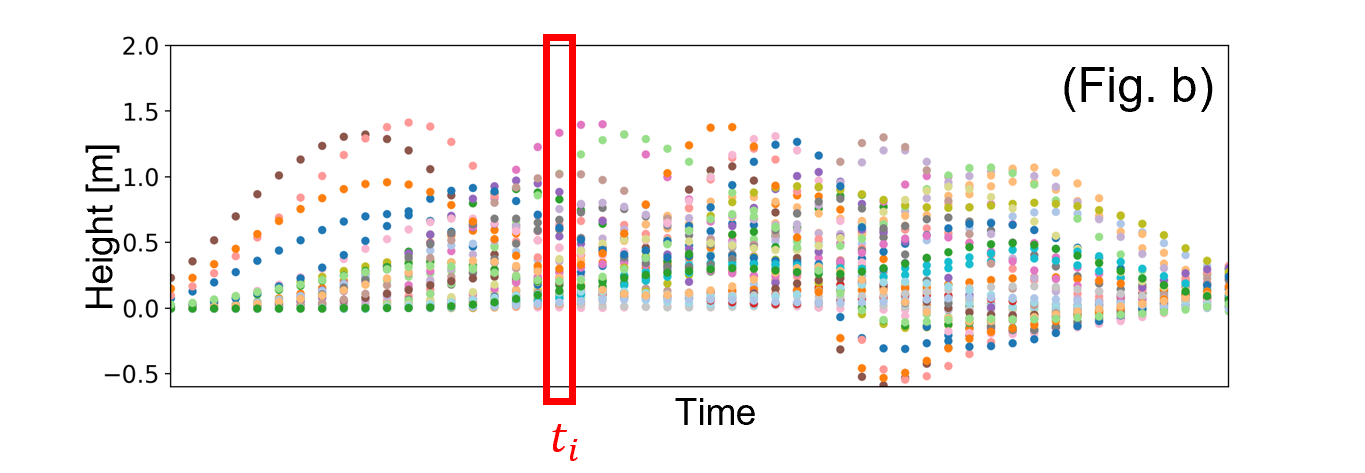
2. Predicting Waveform Data with Multi-Sigma®
Using the AI model trained on waveform data with Multi-Sigma®, we predicted the time series of water level at a given observation point for tsunami heights and source locations that were not included in the training data (the figure below). Compared with the observed values (solid blue line), the predicted waveform produced (red dashed line) reproduced the overall shape as well as the timing and amplitude of the main peaks well, demonstrating a high level of agreement.
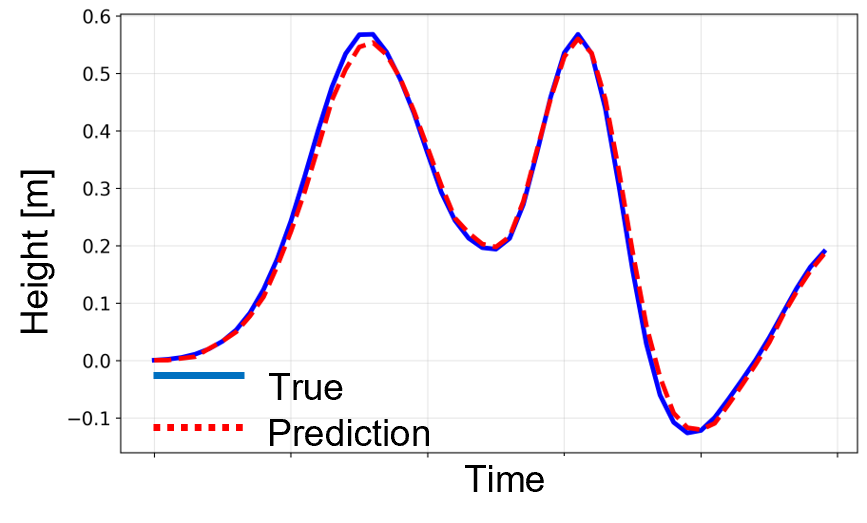
3. Further Ideas for Waveform Data Analysis
In Multi-Sigma®, up to 100 output variables can be handled in a single AI model. Therefore, the discretized points shown in Fig. b can be treated up to 100 points. However, as the observation duration 𝑇 becomes longer, this upper limit of 100 points means that the time step Δ𝑇 inevitably has to become larger. In addition, the tsunami height and source location were simulated within a limited range, but prediction becomes more difficult when parameter values vary over a much wider range or when the number of parameters increases. In that case, an alternative approach is to expand the waveform data into basis functions and have the AI model predict the corresponding coefficients. For further details, please feel free to contact us.
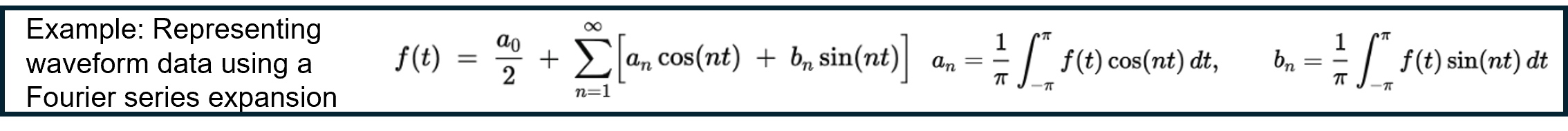
Note: For the tsunami data, we use synthetic data.